
Comparamos 35 obras en el Día del Libro y del idioma español
Por Julián Yanover
El 23 de abril, conmemorando la muerte de Miguel de Cervantes, se celebra tanto el día internacional del libro como del idioma español. Unimos estos dos festejos en este análisis que revisa el vocabulario de 35 libros en busca de los textos más complejos y accesibles para los lectores.
Con este objetivo en mente, hicimos uso de inteligencia artificial y software de procesamiento del lenguaje natural para desmenuzar cada obra y obtener respuestas.

Compartimos a continuación la metodología y la clasificación final.
Qué analizamos
Hicimos una selección de 35 de los libros más reconocidos en español. Intentamos que haya cierta diversidad, que sean de distintas épocas, y con estilos diferentes. Estos son los autores analizados, por país:
Argentina: Ernesto Sábato, Jorge Luis Borges y Julio Cortázar.
Brasil: Paulo Coelho.
Chile: Gabriela Mistral, Isabel Allende, José Donoso y Roberto Bolaño.
Colombia: Gabriel García Márquez y Laura Restrepo.
Cuba: Alejo Carpentier y Zoé Valdés.
España: Almudena Grandes, Ana María Matute, Ángeles Mastretta, Antonio Machado, Arturo Pérez-Reverte, Gustavo Adolfo Bécquer, Benito Pérez Galdós, Carlos Ruiz Zafón, Carmen Laforet, Miguel de Cervantes, Federico García Lorca, Javier Marías, María Dueñas y Miguel Delibes.
Guatemala: Miguel Ángel Asturias.
México: Carlos Fuentes, Elena Poniatowska, Juan Rulfo y Rosario Castellanos.
Nicaragua: Gioconda Belli.
Perú: Mario Vargas Llosa.
Uruguay: Cristina Peri Rossi y Mario Benedetti.
Cómo lo analizamos
- Base de datos con 4.731.006 palabras.
- Software de procesamiento del lenguaje natural (PLN) e inteligencia artificial para registrar y unificar palabras similares vía lematización.
- Sistema de puntaje propio para homogeneizar criterios y evaluar la diversidad léxica.
Los libros fueron guardados, palabra por palabra, en una base de datos.
Realizamos la lematización de cada palabra, que implica llevar todas las variantes que una palabra puede tener a su lema base. Por ejemplo, comió, comerá y comen se agrupan bajo el lema comer. Esta técnica es una herramienta del procesamiento del lenguaje natural que permite que el resultado final sea más fidedigno al contar solo los lemas y no todas las variantes de una misma palabra.
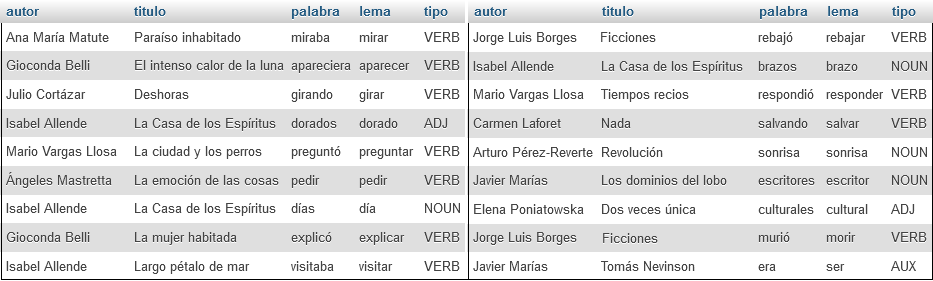
Un vistazo a la base de datos con más de 4 millones de palabras almacenadas y procesadas
El primer problema que enfrentamos fue que, en libros más extensos, generalmente había más cantidad de palabras únicas, pero un menor porcentaje de estas con respecto al total. Es natural: en un libro de 100.000 palabras abordaremos más vocablos, pero al mismo tiempo habrá más repetición que en uno de 5.000.
La manera de resolverlo fue encontrada en colaboración con la inteligencia artificial.
La IA nos presentó algunas metodologías posibles, como dividir la cantidad de lemas distintos por la raíz cuadrada del total de palabras del libro, o de igual manera dividirlo por su logaritmo. Sin embargo, aunque el cálculo era menos influenciado por la extensión del libro, seguía siendo afectado por el número total de palabras de cada publicación.
También contemplamos la opción de comparar solamente muestras de igual tamaño de cada texto, pero esto dejaba en algunos casos el 90% del libro fuera del análisis.
Finalmente, tomamos el camino de ventanas móviles. Lo que hicimos fue desarrollar un código que analizó la diversidad del lenguaje de cada libro en fragmentos de 1.000 palabras, y tomó el promedio total de variedad de lemas como resultado para cada obra. Así, todo el libro quedó dentro del análisis, y se redujeron al máximo los factores que distorsionaban los números finales.
De este modo, obtuvimos un puntaje de diversidad léxica para cada libro, en una escala del 1 al 100, donde mientras más alto el puntaje, representa más amplitud del lenguaje utilizado.