
SQL es la sigla correspondiente a Structured Query Language.
SQL es la sigla que corresponde a la expresión inglesa Structured Query Language (entendida en español como Lenguaje de Consulta Estructurado), la cual identifica a un tipo de lenguaje vinculado con la gestión de bases de datos de carácter relacional que permite la especificación de distintas clases de operaciones entre éstas. Gracias a la utilización del álgebra y de cálculos relacionales, el SQL brinda la posibilidad de realizar consultas con el objetivo de recuperar información de las bases de datos de manera sencilla.
El científico Edgar Frank Codd (1923–2003) fue quien propuso un modelo relacional para las bases de datos y creó un sublenguaje para acceder a los datos a partir del cálculo de predicados. En base al trabajo de Codd, IBM (International Business Machines) definió el lenguaje conocido como Structured English Query Language (SEQUEL).
El SEQUEL se considera el antecesor de SQL, un lenguaje de cuarta generación que se estandarizó en 1986. La versión más primitiva de SQL, por lo tanto, fue la que se bautizó como SQL-86 (también conocida como SQL1).
 Temas
TemasCaracterísticas del SQL
En esencia, el SQL es un lenguaje declarativo de alto nivel ya que, al manejar conjuntos de registros y no registros individuales, ofrece una elevada productividad en la codificación y en la orientación a objetos. Una sentencia de SQL puede resultar equivalente a más de un programa que emplee un lenguaje de bajo nivel.
Una base de datos, dicen los expertos, implica la coexistencia de múltiples tipos de lenguajes. El denominado Data Definition Language (también conocido como DDL) es aquél que permite modificar la estructura de los objetos contemplados por la base de datos por medio de cuatro operaciones básicas. SQL, por su parte, es un lenguaje que permite manipular datos (Data Manipulation Language o DML) que contribuye a la gestión de las bases de datos a través de consultas.
El SQL posibilita la gestión de bases de datos de carácter relacional.
Cómo construir una base de datos eficiente
Toda empresa que apunte a un futuro brillante, con posibilidades de crecimiento y expansión, debe contar con una base de datos, que será diferente en cada caso, ajustándose a las necesidades particulares de cada tipo de negocio, pero que deberá ser confeccionada cuidadosamente, con una estructura sólida y configurable, abierta a potenciales modificaciones sin que esto amenace su integridad.
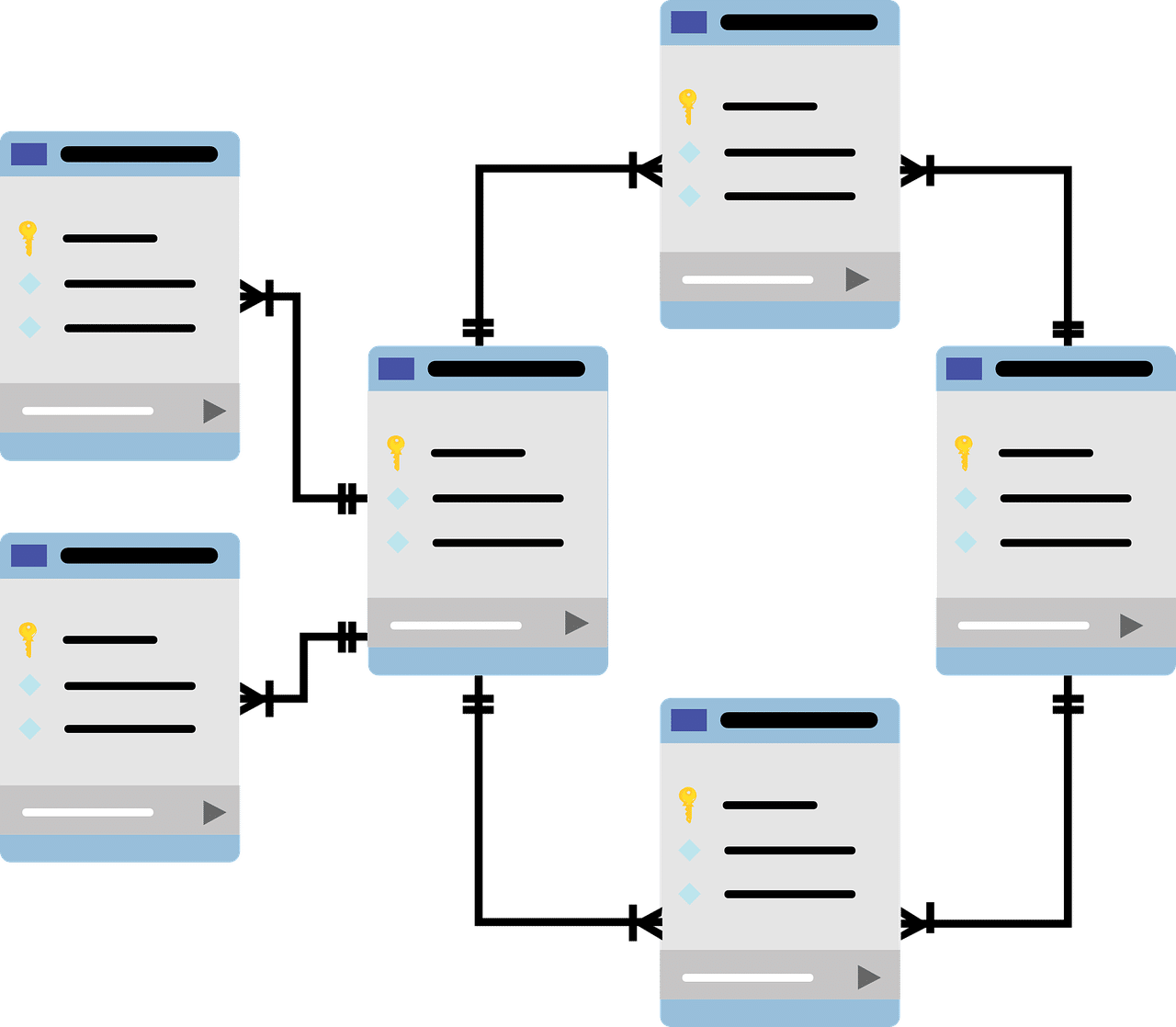
Uno de los puntos básicos a la hora de construir una base de datos es la indexación. Para entender este concepto, veamos brevemente un ejemplo práctico de base: supongamos que una compañía desea almacenar la información personal de sus clientes y hacer un seguimiento de sus transacciones; para ello, una posibilidad consistiría en tener una tabla para sus datos (nombre, apellido, dirección de e-mail, etcétera), otra para la descripción de los productos (nombre del artículo, precio, detalles) y una para las ventas. Antes de pasar a detallar qué campos podrían estar presentes en esta última tabla, cabe mencionar que en las restantes falta un elemento indispensable para una buena organización: una clave única de identificación.
Generalmente llamada ID, suele ser un número entero (sin decimales) y positivo que la base de datos asigna automáticamente a cada nuevo registro (en este caso, cada nuevo cliente o producto) y que nunca se repite, de modo que lo identifique desde su nacimiento (momento de creación) hasta su muerte (cuando se elimine). De esta forma, si tomamos por ejemplo el registro «103 Pablo Bernal [email protected]», notamos que su ID es 103. ¿Cuál es su utilidad? En pocas palabras, buscar un cliente cuyo nombre sea n, su apellido, a, y su e-mail, e, toma mucho más tiempo que pedir a la base que nos devuelva todos los datos del cliente con ID «103». Si bien es probable que en la primera operación especifiquemos toda su información, una vez que el programa lo encuentre, podremos valernos de este número para el resto de las consultas.
Retomando el ejemplo, dado que las tablas de clientes y productos tendrían su ID, relacionarlas con la de ventas resulta muy sencillo; sus campos podrían ser: id de transacción, id de cliente, id de producto, fecha, observaciones. Sin entrar en tecnicismos, es claro que cada venta contiene mucha más información de la que se aprecia a simple vista, ya que, por ejemplo, el id de un cliente nos sirve para acceder a todos sus datos en la tabla correspondiente. En la puesta en práctica, sobra decir que la complejidad puede ser muchísimo mayor, pero es importante comenzar por lo básico para entender la importancia de relaciones sólidas y eficientes.